随着短视频应用火爆全网,现在各种短视频已经占据了全网50%以上的流量,那么如何对短视频分类就成了一个问题。目前,我们使用卷积网络可以有效的对图片进行分类,同时精度也比较高。那么神经网络是否可以对视频分类呢?答案是肯定的,本文带你使用ResNet3D网络来完成视频分类任务。
本文对ResNet3D论文解读和复现,ResNet3D网络主要内容出自以下两篇论文:
《Can Spatiotemporal 3D CNNs Retrace the History of 2D CNNs and ImageNet?》
《Would Mega-scale Datasets Further Enhance Spatiotemporal 3D CNNs》
论文项目地址:
https://github.com/kenshohara/3D-ResNets-PyTorch
1.目标
这里我们先简单介绍一下第一篇论文《Can Spatiotemporal 3D CNNs Retrace the History of 2D CNNs and ImageNet?》的目标。我们已经知道CNN网络在CV领域已经取得了巨大的成功,在大量的图片数据集下,比如ImageNet数据集,CNN网络可以取得较高的精度。那么使用目前已有的视频数据集,将现有的CNN网络的2维卷积核调整为3维卷积核,是否有充足的数据可以满足CNN网络的训练需求?文中主要使用ResNet3D网络对此进行了验证。
第二篇论文《Would Mega-scale Datasets Further Enhance Spatiotemporal 3D CNNs》是在第一篇的基础上进行的工作,其目标是希望验证超大规模的数据集是否可以增强CNN网络的性能。
2.工作内容
在第一篇论文中,论文作者发现只有在Kinetics400这种大规模数据集上,ResNet系列模型才能很好的收敛。在UCF101、HMDB-51和ActivityNet上模型都会出现过拟合的情况,很难训练出高精度的模型。在Kinetics400数据上,随着模型的深度增加,比如在ResNet152之后,精度提升就很微弱了。这里说明了如果有大规模的数据集是可以使用3D的CNN网络进行训练的。既然有了大规模数据集训练好的模型,就可以在小规模的数据集上进行微调训练,作者取得了不错的结果。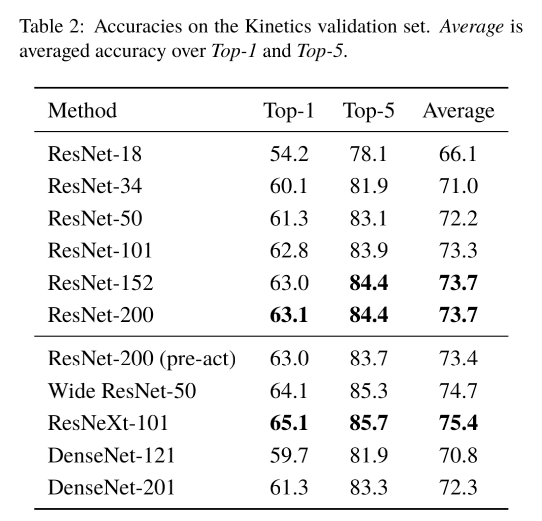
第二篇论文在第一篇论文的基础上,对不同的大规模数据集进行融合,得到了不同的组合超大规模的数据集,分别训练出不同层数ResNet3D网络。保存模型权重可以作为预训练权重,在小规模数据集上进行微调训练,在不同数据集和模型上都得到了不同程度的精度提升。
3.模型结构
通常做图像分类使用的ResNet网络的卷积核一般只是在2D图像上做滑动窗口,计算特征图,卷积核的形状一般为[out_channel, in_channel, W, H]。而在视频分类任务中一般对网络输入的是视频中的一段序列,比如16帧或32帧,这样在原有WH维度上又增加了一个时间T的维度,卷积核的形状为 [out_channel, in_channel, T, W, H]。这时,卷积核不止在2D平面上滑动,还需要在第三个维度T上移动,提取帧之间的关联特征。这样就需要对2D的ResNet进行改造,将其改造为3D的ResNet网络。ResNet3D保持原有的ResNet的整体架构不变,替换每个block中的basicblock或bottleneckblock中的卷积核为Conv3D,同时池化层也需要替换为3D池化。
整体网络结构描述如下:
4.训练方法
第一篇论文中在Kinetics400数据集上训练使用宽和高均为112像素,16帧的RGB图像作为输入样本。同时使用5种不同尺寸的裁剪方式对图像进行随机裁剪,同时添加了随机水平翻转,进行数据增强。使用交叉熵作为损失函数,同时使用SDG优化器,设置正则化系数为0.001,动量系数设置为0.9,起始学习率为0.1。如果在10个epochs之后,验证集的损失没有减小,则学习率除以10。在小数据集上进行模型微调时设置SDG优化器学习率为0.001,同时正则化系数设置为1e-5。同时作者在多次实验得出结论:在训练时,冻结前4个block,只微调第5个block和全连接层的权重可以得到更好的结果。
第二篇论文在第一篇论文训练策略的基础上进行了调整,因为是使用超大规模数据集对模型进行微调,所以其他参数不变,只是将SGD优化器的起始学习率设置为0.003,正则化系数和动量系数保持0.001和0.9。
5.实验结果
通过在多种超大规模数据集和多种模型结构组合训练得出以下结果。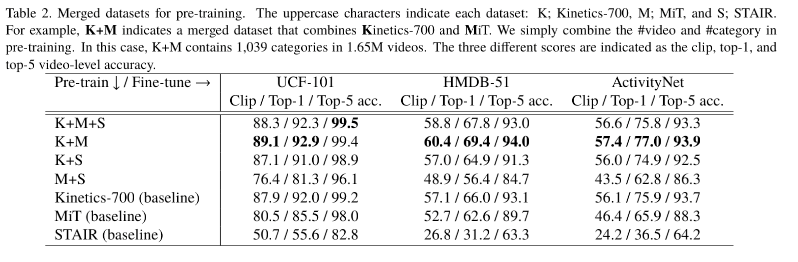
本次复现的条件和目标如下,
预训练模型:K+M数据集上的ResNet50预训练权重
数据集:UCF-101
目标:Top1为92.9%
6.论文复现
项目地址:
https://github.com/txyugood/Paddle-3D-ResNets
1.下载解压数据集
数据集地址数据集地址:
https://aistudio.baidu.com/aistudio/datasetdetail/48916
1 | mkdir dataset/ |
2.视频转换为图片
1 | mkdir /home/aistudio/dataset/UCF-101-jpg/ |
3.转换pytorch预训练模型
1 | pip install torch==0.4.1 |
4.训练网络
在训练过程中进行clips准确率验证,并保存clips准确率最高的模型,最终clips准确率90%。
训练方法:
训练时开启4进程读取,将数据集分为4块,batch_size 为128,以异步方式读取数据进行模型训练。
每次迭代总训练时间为2.3秒左右,数据读取时间为1.8秒左右,
CPU使用率已接近100%,内存占用在80-90%之间。
GPU使用率50%,可见训练瓶颈在CPU读取数据部分,若CPU和内存扩容,还可以继续提升训练速度。
训练使用的优化器为Momentum,学习率0.003,momentun=0.9 L2Decay为0.001.
数据增强方式选择RandomResizedCrop方式。
按照论文中提到的方法,冻结Resnet50网络的conv1、conv2、conv3和conv4,只训练conv5和fc层。
1 | cd Paddle-ResNets/ && python train.py |
5.验证网络
按照论文的方法将视频以16帧为一个clip进行分割,最后计算一个视频的所有clips的平均值作为视频的分类结果。
最后会生成val.json文件供计算top-1准确率使用。这里与pytorch版本代码逻辑一致。
1 | cd Paddle-ResNets/ && python test.py |
6.计算准确率
Top-1准确率为93.55% 超过论文中的92.9%。
1 | cd Paddle-ResNets/ && python eval_accuracy.py |