Relation Net 是 CVPR2018的一篇论文,论文链接:https://arxiv.org/abs/1711.06025。
深度学习在视觉识别任务中取得巨大的成功,文章作者指出训练模型需要大量标注过的图片,同时需要迭代多次去训练参数。每当添加新的物体类别需要花费时间去标注,同时有一些新兴物体类别和稀有物体类别可能根本不存在大量的标注过的图片。而人类是只要很少的认知学习就可实现小样本(FSL)和无样本学习(ZSL)。作者举了一个例子,小孩子只要在一张图片或一本书里认识了斑马,或者只是听到描述斑马是一种”条纹马”,就可以毫无困难的识别出斑马这种动物。为了解决深度学习中样本很少模型的分类效果就会很差的问题,同时又受到人类的小样本和无样本学习能力带来的启发,小样本学习又恢复了一些热度。深度学习中的Fine-tune技术可以用于一些样本比较少的情况,但是在只有一个或者几个样本的情况下,即使使用了数据增强和正则化技术,仍然会有过拟合的问题。目前其他的小样本学习的推理机制又比较复杂,所以论文作者提出了一个可以端到端训练,并且结构简单的模型 Relation Net。
在 FSL 任务中,一般将数据集分为 training set /support set /testing set 三个数据集。support set和 testing set有共同的标签,training set里面不包涵 support set和 testing set的标签。在 support set 中有 K 个标注过的数据和 C 个不同的类别,则称作为 C-way K-shot。在训练的过程中从 training set 中选取 sample set /query set 对应support set/testing set,具体方法后面训练策略里会详细说明。
Relation Network由 embedding model 和 relation model 组成。Relation Network 的核心思想是首先通过embedding model分别提取 support set 和 testing set中图像的特征图,然后将特征图中代表通道数的维度进行拼接,得到一个新的特征图。然后把新的特征图送入 relation model 进行运算得到 relation score,这个值代表了两张图的相似度。
下图为5-way 1-shot 的情况下接受1个样本的网络结构与流程。5张sample set 中的图片与1张 query set 中的图片会分别的通过 embedding model 提取特征并拼接,得到5个新的特征图,然后送入 Relation Net 进行计算 relation score,最后会得到一个 one-shot 的向量,分数最高的代表对应的类别。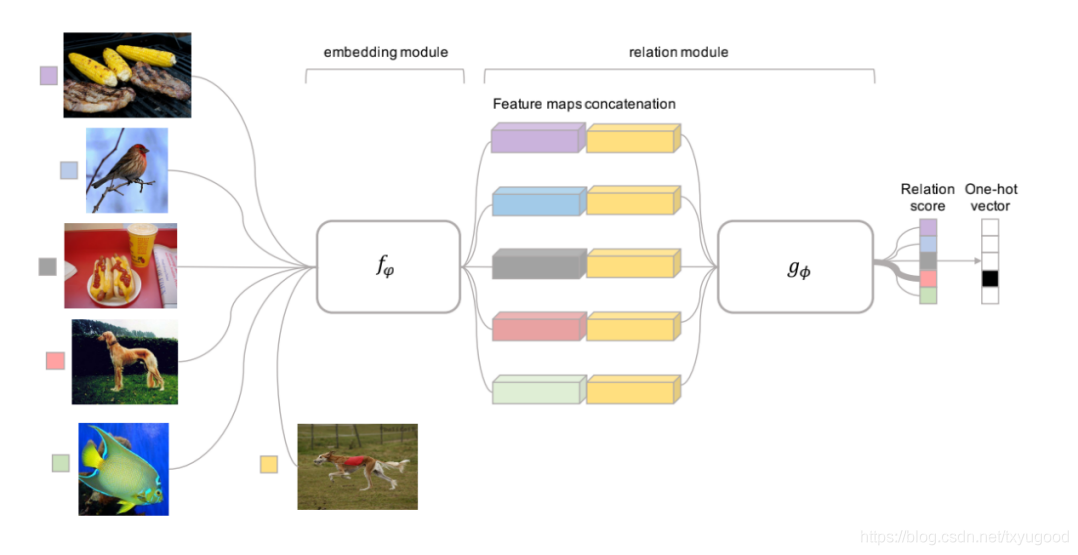
训练使用的损失函数也比较简单,使用均方误差作为损失函数。公式中 ri,j代表图片 i与 j 的相似度。yi 与 yj代表图片的真实标签。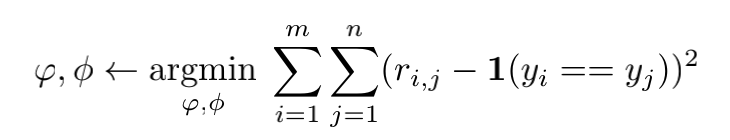
基于飞桨复现Relation Network
Relation Network 模型结构定义请查看:
https://github.com/txyugood/paddle_RN_FSL/blob/master/RelationNet.py
下面我将复现的技术细节与各位开发者分享。
1.搭建 Relation Network 网络
模型由embedding model 和 relation model 两部分组成,两个网络都主要由 【Conv+BN+Relu】模块组成,所以首先定义一个 BaseNet类,并在其中实现conv_bn_layer方法,代码如下:
1 | class BaseNet: |
飞桨支持静态图和动态图两种网络定义模式,这里我选用的静态图,以上代码就是定义了一个卷积神经网络中最经常出现的 conv_bn 层,但要注意的是 batch_norm 层的 momentum 设置为1,实现的效果就是不记录全局均值和方差。
具体参数含义如下:
- input:传入待卷积处理的张量对象
- num_filter:卷积核数量(输出的卷积结果的通道数)
- filter_size:卷积核尺寸
- stride: 卷积步长
- groups:分组卷积的组数量
- padding:填充大小,这里设置为0,代表卷积后不填充。
- act:接在 BN 层后的激活函数,如果为 None,则不使用激活函数
- name:在运算图中的对象名称
接着我们定义 Relation Network 中的 embedding model 部分。
1 | class EmbeddingNet(BaseNet): |
首先创建一个EmbeddingNet类,继承BaseNet类,它就继承了conv_bn_layer方法。在EmbeddingNet中定义 net方法,它的参数 input 代表输入的图像张量,这个方法用来创建网络的静态图。输入的 input 首先经过一个【Conv+BN+relu】的模块得到特征图embed_conv1,然后进行了一次最大值池化操作。池化的作用的是在保留重要特征的前提下缩小特征图,后面的卷积和池化操作作用与此相同。最后embed_conv4输出的特征图形状是[-1,64,19,19]一共4个维度,第1个纬度代表了 batch_size,因为 batch_size 在创建静态网络时是不确定的,所以用-1来表示可以是任意值。第2个纬度代表了特征的图的通道数,经过 embedding model后,特征图的通道数为64。最后第3和第4个维度代表了特征图的宽度和高度,这里是19x19。
Relation model 代码部分如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39class RelationNet(BaseNet):
def net(self, input, hidden_size):
conv = self.conv_bn_layer(
input=input,
num_filters=64,
filter_size=3,
padding=0,
act='relu',
name='rn_conv1')
conv = fluid.layers.pool2d(
input=conv,
pool_size=2,
pool_stride=2,
pool_type='max')
conv = self.conv_bn_layer(
input=conv,
num_filters=64,
filter_size=3,
padding=0,
act='relu',
name='rn_conv2')
conv = fluid.layers.pool2d(
input=conv,
pool_size=2,
pool_stride=2,
pool_type='max')
fc = fluid.layers.fc(conv,size=hidden_size,act='relu',
param_attr=ParamAttr(name='fc1_weights',
initializer=fluid.initializer.Normal(0,0.01)),
bias_attr=ParamAttr(name='fc1_bias',
initializer=fluid.initializer.Constant(1)),
)
fc = fluid.layers.fc(fc, size=1,act='sigmoid',
param_attr=ParamAttr(name='fc2_weights',
initializer=fluid.initializer.Normal(0,0.01)),
bias_attr=ParamAttr(name='fc2_bias',
initializer=fluid.initializer.Constant(1)),
)
return fc
创建一个RelationNet类,它同样继承于 BaseNet 类,继承了conv_bn_layer方法。在 net 方法中,模型的前面几层与 embeding model 中类似使用【Conv+BN+Relu】模块进行特征提取,在最后使用两层全连接层,将特征值映射为一个标量relation score,代表了两个图片的相似度。
在训练过程中,sample set 中图片和 query set 的图片经过 embedding model后都得到了形状为[-1,64,19,19]的特征图,在送入 relation model 之前需要进行拼接,这段代码略有些复杂,下面我分段解释一下。
1 | sample_image = fluid.layers.data('sample_image', shape=[3, 84, 84], dtype='float32') |
这部分代码是将 sample image和 query image的张量在batch_size 的纬度上拼接得到张量sample_query_image,一起送到 embedding model 中去提取特征,得到sample_query_feature。
1 | sample_batch_size = fluid.layers.shape(sample_image)[0] |
这部分代码取 image 张量的0维度作为 batch_size。
1 | sample_feature = fluid.layers.slice( |
由于之前图片进行了拼接,所以在特征之后,同样需要在sample_query_feature的 batch_size 对应的0维度上进行切片,分别得到sample_feature 和query_feature。这里如果 K-shot 大于1时,需要对 sample_feature改变形状,然后在 K-shot 对应的1维度上对 K-shot 个张量求和并删除该维度,这时 sample_feature的形状就变成为[C-way,64,19,19]。这时 sample_batch_size 的值应该为 C-way。
1 | sample_feature_ext = fluid.layers.unsqueeze(sample_feature, axes=0) |
因为 sample set 中的每一张图片特征都需要与 C 个类型的图片特征进行拼接,所以这里通过unsqueeze新增一个维度。根据 expand 接口的参数要求,这里新建一个 query_shape 张量实现复制 sample_feature 张量query_batch_size 次得到一个形状为[query_batch_size, sample_batch_size, 64, 19, 19]的张量。
1 | query_feature_ext = fluid.layers.unsqueeze(query_feature, axes=0) |
同上面的操作一样,query set 的特征也需要新增一维度,这里需要复制 sample_batch_size 次。值得注意的是,如果 k-shot 大于1的情况下,因为之前已经做过 reduce_mean 操作,所以要使sample_batch_size除以 k-shot得到新的sample_batch_size。最后通过复制得到一个[sample_batch_size, query_batch_size, 64, 19, 19]的张量。
1 | query_feature_ext = fluid.layers.transpose(query_feature_ext, [1, 0, 2, 3, 4]) |
最后通过transpose方法进行转置使sample_feature_ext和query_feature_ext形状一致,最后对两个特征进行拼接和修改形状得到一个形状为[query_batch_size x sample_batch_size, 128, 19, 19]的张量relation_pairs。
1 | relation = RN_model.net(relation_pairs, hidden_size=8) |
最后将之前拼接的特征送入 relation model 模块,首先会得到一个query_batch_size x sample_batch_size长度的向量,然后改变形状得到[query_batch_size, sample_batch_size]的张量(sample_batch_size 实际上等于 C-way), sample_batch_size长度的向量以 one-hot 的形式表示出每一个 query image 的类别。
损失函数的代码如下:
1 | one_hot_label = fluid.layers.one_hot(query_label, depth=c_way) |
首先将 query image 的标签 query_label 转换为 one-hot 的形式,之前得到的relation也是 one-hot的形式, 然后计算relation和one_hot_label的MSE得到损失函数。
2.训练策略
在 FSL 任务中,如果只使用 support set 去训练,也可以对 testing set 进行推理预测,但是由于 support set 中样本数量比较少,所以分类器的性能一般不好。所以一般使用training set进行训练,这样分类器会有一个比较好的性能。这里有一个有效的方法,叫做 episode based training。
episode based training的实现步骤如下:
- 训练需要循环迭代 N 个 episode,每1个 episode 会在 training set 中随机选取 C 个类别的中的 K 个数据,组成1个sample set数据集。C和 K 对应 support set 中的 C-way K-shot,一共有 C x K个样本。
- 然后在 C 个类别中剩余的样本中随机选取几个样本作为 query set, 进行训练。
对于 5-way 1-shot学习,sample set 的 batch_size 选择的是5,query set 的 batch_size 选择的是15。对于5-way 5-shot学习,sample set 的 batch_size 选择的是25(每个类别5张图),query set 的 batch_size 选择的10。
对于训练的优化器,选择的是 Adam优化,学习率设置为0.001。
对于数据增广,在数据读取时对 sample set 和 query set 的图像都使用了 AutoAugment 的方法来增加数据的多样性。
3.模型复现效果
验证时的数据集只使用了论文中实验用的 minImageNet,共有100个分类,每个分类600张图片。这个100个分类分别划分为 training/validation/testing 三个数据集,数量分别为64、16和20。
文章中提到模型在minImageNet的testing 数据集上准确率如下:
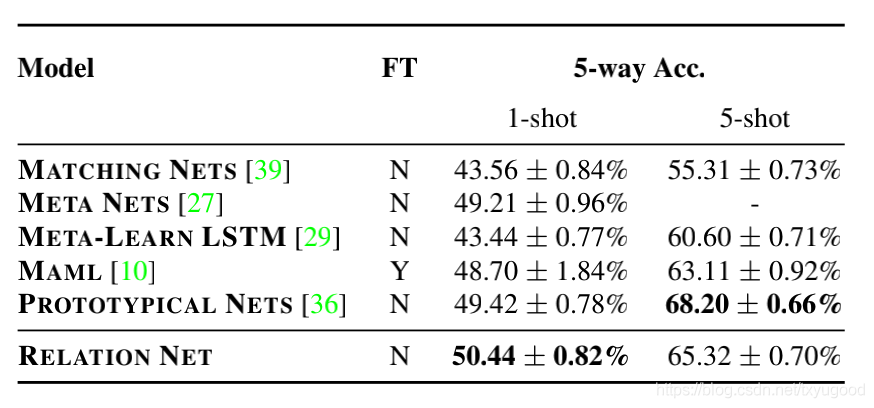
Relation Net 在5-way 1-shot 和 5-way 5-shot 分别达到了50.44和65.32左右的准确率。
同样使用基于飞桨实现的 Relation Net 在minImageNet的testing 数据集上的
5-way 1-shot 准确率:
5-way 5-shot 准确率:
与论文中的准确率一致,模型复现完成。
代码地址:https://github.com/txyugood/paddle_RN_FSL